
Tecnologia
Tecnologia do Google de aprimoramento de imagens impressiona
Google trabalha em duas novas abordagens, baseadas em IA e machine learning, para transformar fotos de baixa escala em imagens de alta resoluçãoBy - Igor Shimabukuro, 31 agosto 2021 às 18:23
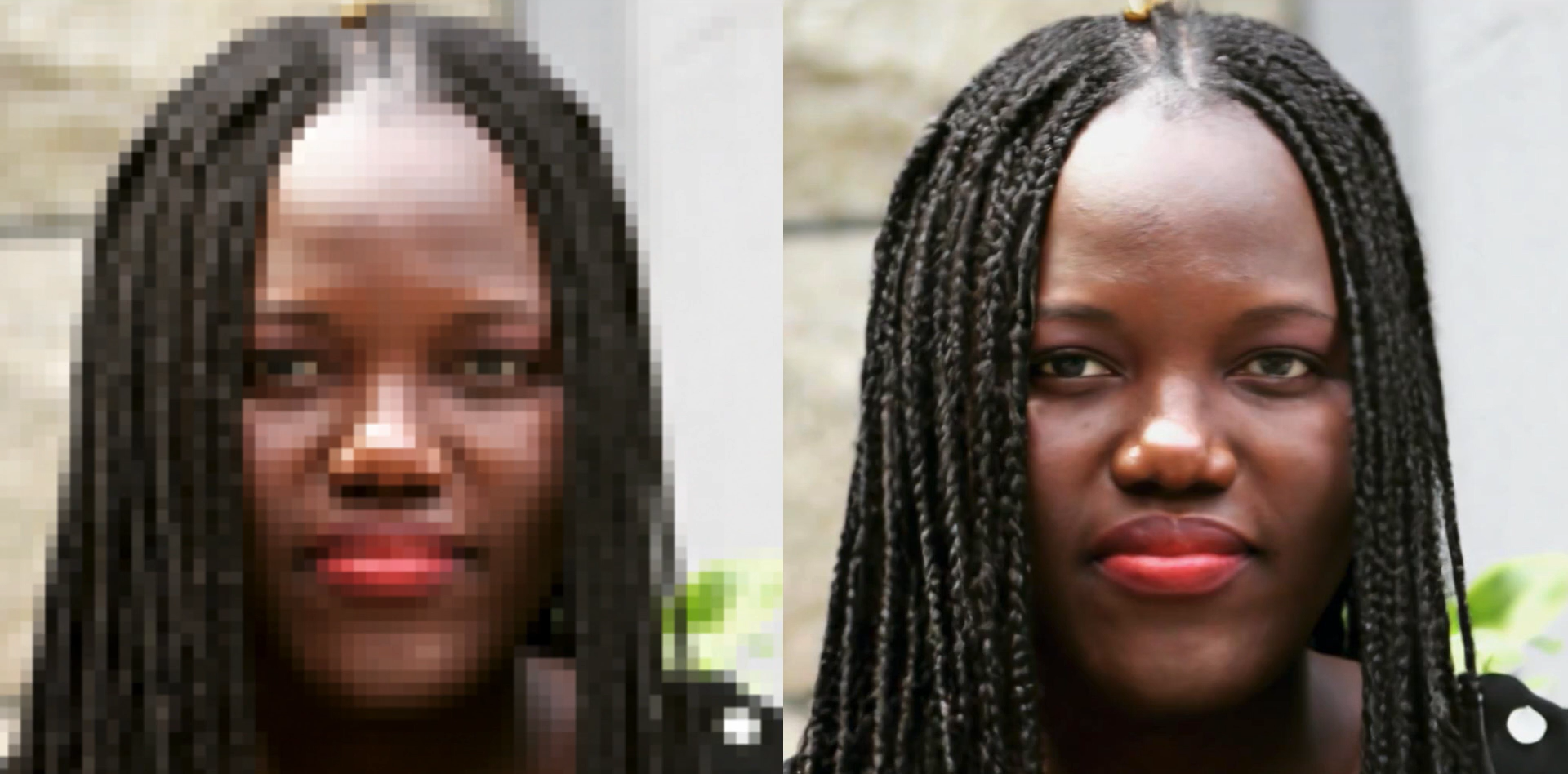
É incrível como os avanços tecnológicos baseados em machine learning e inteligência artificial (IA) têm permitido diversas melhorias no aprimoramento de imagens. Prova disso, é a mais recente tecnologia do Google, capaz de transformar fotos borradas e de baixa escala em imagens de alta resolução com detalhes surpreendentes.
A tecnologia, na verdade, foi revelada em julho, no blog oficial da big tech. Na postagem, intitulada de “Geração de imagens de alta fidelidade usando modelos de difusão”, a companhia de Sundar Pichai detalha um pouco mais sobre os avanços feitos por sua equipe na super-resolução de imagem.
Por falar dela, o processo envolve um modelo de machine learning, que é treinado para transformar fotos de baixa resolução em imagens de alta resolução, rica em detalhes. Como consequência disso, a tecnologia permite restauração de fotos antigas da família e até o aprimoramento de imagens médicas, por exemplo.
Para isso, o Google tem explorado um conceito chamado de “modelos de difusão”, proposto inicialmente em 2015. Até recentemente, a companhia optou por priorizar um método chamado de “modelos generativos profundos”, mas a nova abordagem parece ser muito mais eficiente quando humanos são solicitados a julgar os resultados das máquinas.
Nova abordagem do Google
A primeira dessas “novas” abordagens chama-se SR3 ou Super-Resolução via Refinamento Repetitivo. Basicamente, o modelo é treinado em um processo de corrupção de imagem, no qual o ruído é adicionado progressivamente a uma imagem de alta resolução até que apenas o “ruído puro” permaneça.
O modelo então aprende a reverter esse processo, iniciando com o ruído puro e removendo os ruídos até alcançar uma distribuição alvo baseada na orientação da imagem de baixa resolução (de entrada). O resultado deste método pode ser conferido no vídeo abaixo:
Os produtos apontam que o SR3 executado pelo Google funciona melhor em retratos e imagens naturais. Quando utilizado para aumentar a escala em oito vezes de rostos, por exemplo, a “taxa de confusão” da máquina pode chegar a 50%.
Já a segunda abordagem, conhecida como CDM, foi construída com base em vários modelos de difusão. O princípio é parecido: transformar uma imagem de baixa resolução em uma foto de alta resolução. No entanto, o modelo gera sequências em cascatas, capazes de aumentar as escalas das imagens gradativamente.
Nos exemplos publicados pelo Google, uma imagem borrada de 32×32 pode se tornar uma foto bem realista de 256×256. Em outro experimento, uma foto 64×64 foi transformada em uma imagem 1024×1024, rica em detalhes.

Divulgação: Google

Divulgação: Google
Os resultados podem deixar qualquer indivíduo de queixo caído. É claro que erros podem ser vistos — principalmente em detalhes como armações de óculos ou acessórios presentes nos close-ups —, mas grande parte dessas imagens certamente seriam consideradas como originais à primeira vista.
E a boa notícia é que mais avanços são planejados. Ao que parece, o Google pretende aprimorar os potenciais do SR3 e do CDM de modo a ampliar os desenvolvimentos de modelagem generativa. Se a tecnologia já chegou a este ponto, é difícil imaginar do que ela será capaz em um futuro próximo.
Fonte: PetaPixel




Comentários